

Speaker Identification
Speaker Recognition is the identification of a person from characteristics of voices. Recognizing the speaker can simplify the task of translating speech in systems that have been trained on specific voices or it can be used to authenticate or verify the identity of a speaker as part of a security process. With over 450 known speakers contributing in varying degree of content, the sample set of speakers is narrowed down to 200 speakers with at least 6 spoken utterances, that are distributed in the Dev and Eval Sets. The primary focus of this challenge will be to identify Speakers with drastically varying duration of speech
Instructions
Performance Metrics
The SID Task will be evaluated for Accuracy of the Top-5 system predictions for a given input file.
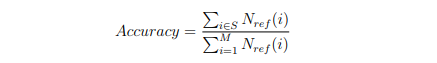
where, S = {k ∈ [1, M] : Nref (k) ⊆ Nsys(k)} and M is the total number of input segments.
For additional details about labeling, please consult the documentation.
Baseline
For information about FSC - Phase 1 baseline results, Pleaseclick here.
Baseline systems will be announced soon!
References
Coming soon!!