

Automatic Speech Recogntion
The goal of the ASR task is to automatically produce a verbatim, case-insensitive transcript of all words spoken in an audio recording. ASR performance is measured by the word error rate(WER), calculated as the sum of errors (deletions, insertions and substitutions) divided by the total number of words from the reference.
Performance Metrics
Manual transcription for the Dev and Eval sets has been carried out using hand annotated SAD labels as a starting point.
An overall Word Error Rate (WER) will be computed as the fraction of token recognition errors per maximum number of reference tokens (scorable and optionally deletable tokens):
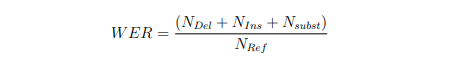
where,
- NDel : number of unmapped reference tokens (tokens missed, not detected, by the system)
- NIns : number of unmapped system outputs tokens (tokens that are not in the reference)
- NSubst : number of system output tokens mapped to reference tokens but non-matching to the reference spelling
- NRef : the maximum number of reference tokens (includes scorable and optionally deletable reference tokens)
Track 1
Track 1 for Automatic Speech Recognition consists of audio streams each of length 30 minutes. Each audio file has a corresponding transcript consisting of long audio segments which provides speaker information, However the user will have no ground truth diarized labels and are encouraged to build their own SAD/Diarization systems.
Baseline
For information about FSC - Phase 1 baseline results, Pleaseclick here
Baseline systems will be announced soon!
References
Coming soon!!
Track 2
Track 2 for Automatic Speech Recognition consists of audio segments that are diarized.
Baseline
Baseline systems will be announced soon!
References
Coming soon!!