

Speaker Diarization
Speaker diarization has received much attention by the speech community, and while many of the currently developed state-of-the-art systems for telephone speech, broadcast news and meetings,their performance does not translate to naturalistic speech in highly degraded noise environments. This FS Phase-02 challenge will focus on evaluating systems on per file Diarization Error Rate (DER).
Performance Metrics
Diarization error rate (DER), introduced for the NIST Rich Transcription Spring 2003 Evaluation (RT-03S), is the total percentage of reference speaker time that is not correctly attributed to a speaker, where correctly attributed is defined in terms of an optimal one-to-one mapping between the reference and system speakers. More concretely, DER is defined as:
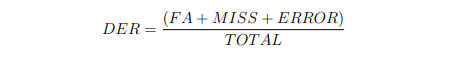
where,
- TOTAL is the total reference speaker time; that is, the sum of the durations of all reference speaker
- FA is the total system speaker time not attributed to a reference speaker
- MISS is the total reference speaker time not attributed to a system speaker
- ERROR is the total reference speaker time attributed to the wrong speaker segments
The per-file results for DER will be considered for evaluation. For additional details about scoring and tool usage, please consult the documentation.
Track 1
Track 1 for Speaker Diarization consists of audio streams each of length 30 minutes. Each audio file has a corresponding transcript which provides speaker information, However the user will have no ground truth labels and are to build their own Speech Activity Detection System to achieve this task.
Baseline
For information about FSC - Phase 1 baseline results, Pleaseclick here
| Set type | DER |
|---|---|
| Development Set | 79.723% |
| Evaluation Set | 88.276% |
References
Coming Soon!!.
Track 2
Track 2 for Speaker Diarization consists of audio streams each of length 30 minutes. Each audio file has a corresponding transcript which provides speaker information, and the ground truth labels for Speech Activity Detection for each audio file. The user can use the reference SAD labels to train and test their systems.
Baseline
| Set type | DER |
|---|---|
| Development Set | 68.688% |
| Evaluation Set | 67.912% |
References
Coming Soon!!.